The biggest frustration with present day LLM interactions is their lack of short term memory, which can break any experience you are having with them.
We wondered if we could introduce a persistent data store in a novel way. So we set out to build a simple text-based role playing game, Starship Bridge, asking ChatGPT to be our game master and story teller. And we asked it to track all of this in a shared JSON object, passed back and forth.
It was a lot to ask, and the models struggled, but we found out some interesting things along the way. This article covers our initial set-up and testing, part 2 will cover our optimization efforts.
Our goal was to create a shared, persistent data store within the request and response objects of a LLM.
We constructed a role-playing scenario encoded in JSON, initialized with specific starting values. A simple game client was developed to pass user utterances to the machine learning model. These utterances were encapsulated within a prompt template, directing the scenario with the LLM and supplemented by tracking data in JSON format. The messages array passed to the model included previous responses from the user and from the other characters in the game (present in previous LLM responses). For testing and experimentation, features were integrated to edit game prompts and modify model settings while playing.
With such a slow core loop, making UI model changes and re-testing was too onerous and so we instead build a testRunner in Google Collab that pushed test results into our Google Drive. We provided these to ChatGPT's Advanced Data Analysis Plug-in to analyze and visualize.
Role-play Scenario: Spacecraft Crew. I am the captain and i just said: [user utterance] Simulate the remaining crew based on the accompanying JSON data. Required output: Update and return the JSON in the same exact format, do not add or remove data fields, with responses from different crew members only if their response is interesting and important. Also update crew mood and write a new situationSummary. JSON:
In our first experiment, we did 100 invocations of our starting values using ChatGPT 4. The average response time was 15 seconds, and ranged from 12 to 20.
We created a scoring rubric, and the model did quite well with an average score of 69.5/100, and a range of 48-83%.
Crew metrics were very good with an average of 86% change rate. Ship metrics did worse with 22% change rate, and card metrics were lacking, with only a 54% change rate (which essentially breaks the game).
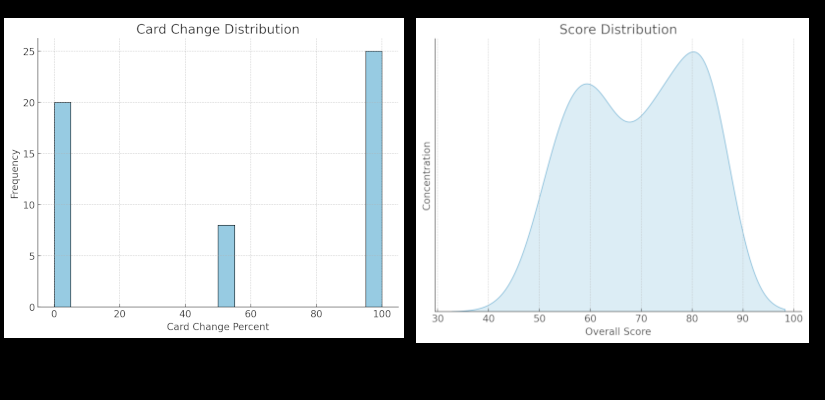
3.5 turbo did not fare well, with average response times over 21 seconds, and the overall score averaging only 34%. This model was not consistent in its performance or return of well structured JSON, and it did not change much of the data, other than the situation_summary. This model often returned just a single message from the point of view of a character, and dropped the JSON tracker all together.
Various problems were encountered, especially by the 3.5 model. ChatGPT 4 was pretty good at doing as asked, but there were still game-breaking issues.
Occasionally the models did not return any tracking JSON. Most of the time when this happened, what they did return was a message from one game character or the ship_summary, without the tracking JSON.
In other instances, the returned JSON was malformed, usually just incomplete, but occasionally modified.
Frequently the models changed some of our tracking data, but not all of it, even when appropriate to do so.
While ChatGPT 4 did well on average, it was extremely variable.
At times the models did not seem to understand what was going on, and frequently they mixed up the roles of the characters they were representing.
The models often gave us back repetitive responses.
The API exhibited fluctuating response times
Latency was bad to very bad.
It was immediately clear that the performance the public API, when asked to do this much, was not going to work for an interactive application. It was also clear that chatGPT 4 was needed for it to work at all, 3.5 turbo failed consistently at the task and was even slower. We also identified that there was a large variability in the success of the request.
Our next steps are optimization. How can we change the prompt and the tracking JSON to make this use case work better? And can chatGPT help us with this?